Construire des Small LLMs experts sans exploser les coûts 🚀
📚 Petit détour par la recherche. Le sujet est technique, mais particulièrement éclairant sur l’avenir des LLMs locaux et des architectures on-premise.
Je vais revenir aujourd’hui sur une étude intitulée “Building Domain-Specific Small Language Models on a Shoestring via Guided Data Generation”, réalisée par des chercheurs de Hitachi Ltd. et publiée pour KDD 2025.
Cette recherche démontre qu’il est possible d’atteindre des performances de très haut niveau avec des modèles légers, à condition de travailler intelligemment sur la donnée plutôt que de chercher à empiler des milliards de paramètres.
Le vrai frein des LLMs locaux
L’adoption des LLMs en local ou à la périphérie (edge computing) est aujourd’hui freinée par deux facteurs majeurs :
- le manque de données de qualité réellement spécialisées
- le coût prohibitif du calcul nécessaire pour entraîner des modèles généralistes
La proposition de cette étude est simple mais radicale :
👉 moins de paramètres, plus d’intelligence dans la donnée.
DiagnosticSLM : petit modèle, grandes performances
Les chercheurs de Hitachi ont ainsi produit un modèle spécialisé de 3 milliards de paramètres, nommé DiagnosticSLM, capable de rivaliser avec des modèles bien plus massifs.
Leur approche repose sur un pipeline de génération et d’alignement de données extrêmement structuré.
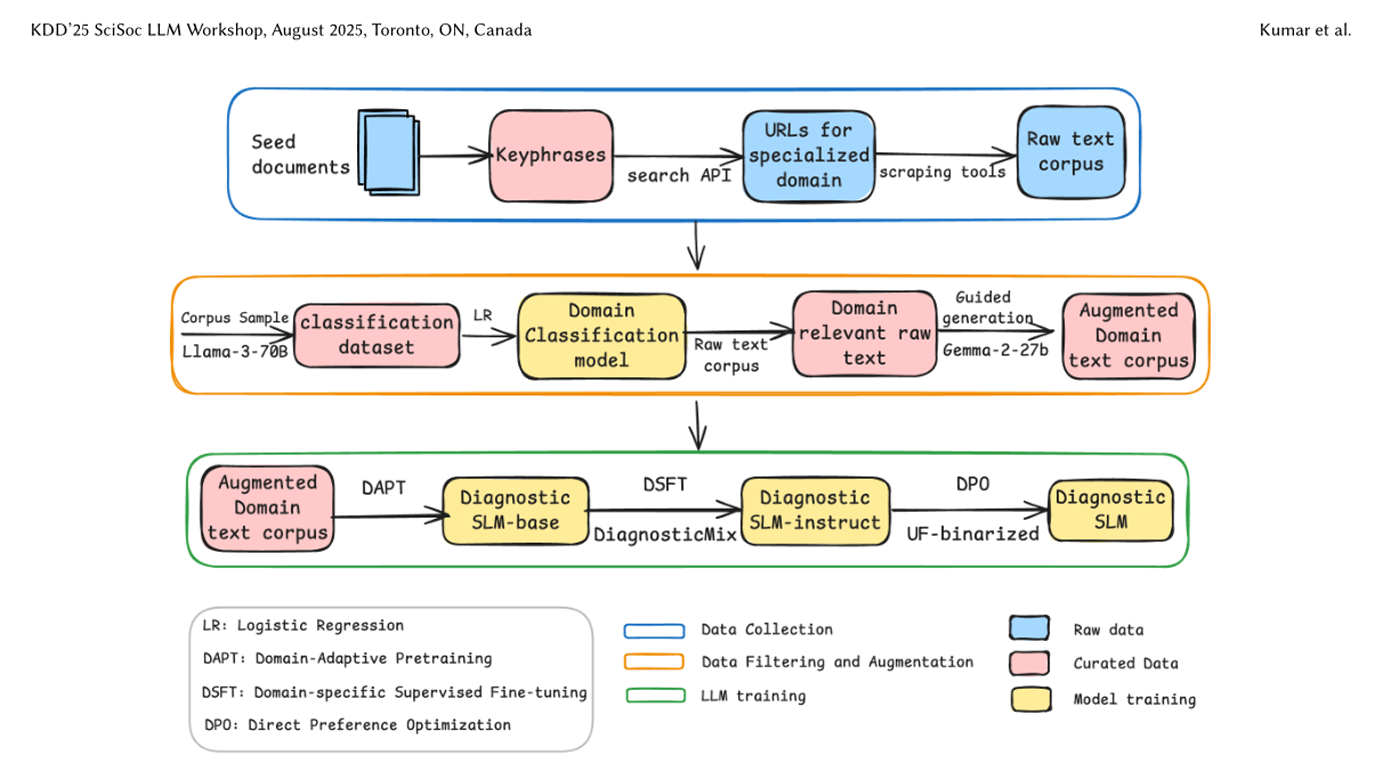
1. Démarrer petit, mais pertinent
Un seed minimal de documents internes spécialisés est utilisé pour extraire les mots-clés techniques essentiels du domaine.
Pas de scraping massif et bruyant.
Juste de la matière première ciblée.
2. Le modèle “professeur”
Un modèle puissant joue ensuite le rôle de teacher model (ici Gemma-2-27B).
Son rôle :
- enrichir le corpus brut
- nettoyer les formulations
- injecter une profondeur technique absente des contenus web généralistes
Ce n’est pas la taille du dataset qui compte, mais sa densité informationnelle.
3. L’alignement progressif du modèle
Vient ensuite un enchaînement de techniques souvent citées, mais rarement bien expliquées.
🔸 Domain-Adaptive Pre-training (DAPT)
On part d’un modèle déjà compétent (ici Llama-3.2-3B) et on prolonge son entraînement sur un corpus brut spécialisé pour lui faire assimiler le jargon et les concepts du domaine.
🔸 Domain-Specific Supervised Fine-Tuning (DSFT)
Une fois le langage compris, on entraîne le modèle à répondre à des instructions concrètes à l’aide de milliers de paires Instruction / Réponse.
Exemple :
“Diagnostique ce bruit de claquage moteur”
→ “Vérifiez en priorité les poussoirs hydrauliques…”
Le modèle devient alors capable de :
- classifier des pannes
- générer des procédures
- répondre à des questions techniques précises
🔸 Direct Preference Optimization (DPO)
Dernière étape : affiner le comportement du modèle via des paires de réponses préférées / rejetées, sans passer par la lourdeur du RLHF classique.
C’est une approche plus simple, plus stable et souvent plus efficace.
Des résultats qui parlent
DiagnosticSLM (3B) atteint 45,32 % d’exactitude, dépassant :
- Ministral-8B (42,81 %)
- et faisant jeu égal avec Gemma-2-9B
Il conserve également une avance nette sur les tâches de Question-Réponse face à Phi-4-mini ou Qwen2.5-3B.
À paramètres comparables, le gain est clair.
Un coût de calcul divisé par 80
♻ Le plus impressionnant reste le coût :
- 5 600 heures GPU pour l’ensemble du pipeline
- soit 1,2 % des ressources nécessaires pour entraîner un modèle équivalent depuis zéro
- contre environ 460 000 heures GPU en entraînement full-scratch
C’est exactement ce qui rend cette approche viable pour :
- l’edge computing
- les déploiements industriels
- les environnements contraints (embarqué, on-prem, souverain)
Ce que j’en retiens
Cette étude illustre parfaitement un changement de paradigme :
👉 L’avenir n’est pas aux modèles toujours plus gros, mais aux modèles plus intelligemment entraînés, profondément alignés sur leur domaine.
Pour qui s’intéresse aux Small LLMs experts, à l’IA locale ou aux architectures sobres, c’est une lecture incontournable.
Personnellement, ça me donne beaucoup d’idées. 😊
![]()
Si vous souhaitez une application mobile, une automatisation ou des conseils pour booster votre entreprise, n’hésitez pas à nous contacter et parlons-en ensemble. 😊