L’ère des Small LLMs experts « On-Device » 📱
📱 L’ère des Small LLMs experts “On-Device”
En intelligence artificielle, une règle devient de plus en plus évidente :
quand c’est vous qui payez, la taille du modèle compte réellement.
L’industrie est en train d’opérer une mutation stratégique. Après plusieurs années de course au gigantisme, les modèles généralistes laissent progressivement place à des SLMs (Small Language Models), conçus pour être précis, spécialisés et économiquement soutenables.
La taille du modèle dicte directement l’équation de votre infrastructure. La métrique clé n’est plus seulement la performance brute, mais la densité d’intelligence par euro ou dollar dépensé.
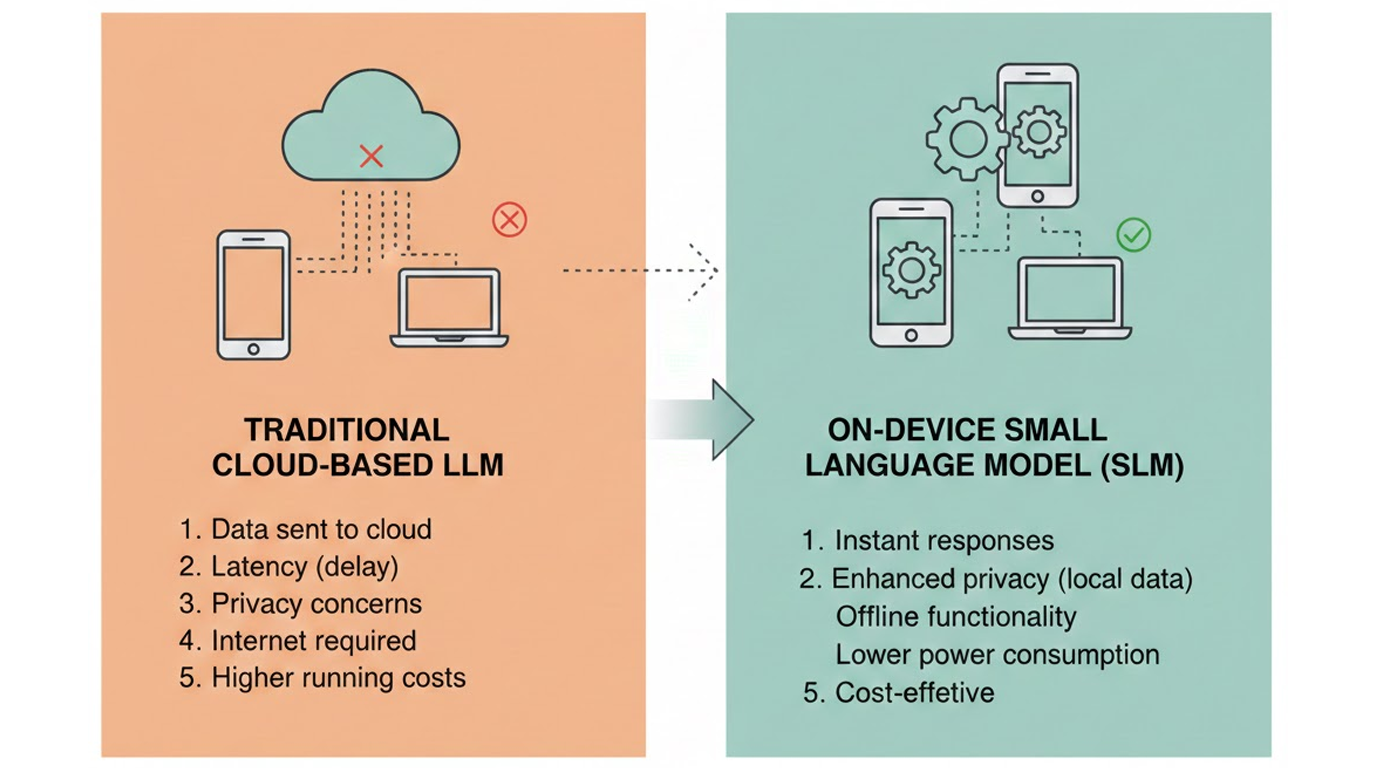
Ces modèles compacts, souvent inférieurs à 8 milliards de paramètres, ne sont pas seulement moins chers ou moins gourmands.
Ils deviennent portables, et ouvrent la voie à de nouveaux usages nomades.
Le rôle clé des NPU
Les téléphones et ordinateurs portables récents intègrent désormais des NPU (Neural Processing Units).
Ces puces sont spécifiquement conçues pour accélérer les réseaux de neurones avec une efficacité énergétique redoutable. Contrairement aux CPU ou GPU généralistes, elles permettent :
- une consommation maîtrisée
- une exécution parallèle optimisée
- une latence extrêmement faible
Résultat : il devient possible d’exécuter des tâches complexes directement sur l’appareil de l’utilisateur, sans dépendre du cloud.
C’est l’avènement de l’IA de poche.
Trois ruptures majeures
Cette approche locale et experte change la donne sur trois points critiques.
🔸 Confidentialité par conception
Les données sensibles (santé, finance, messages, documents internes) ne quittent jamais l’appareil.
Le traitement est effectué intégralement on-device, garantissant une souveraineté totale des données.
Ce n’est plus une promesse contractuelle, mais une réalité technique.
🔸 Indépendance et latence nulle
L’IA fonctionne en mode offline.
Plus besoin de connexion internet pour bénéficier d’un assistant intelligent.
La latence réseau disparaît, remplacée par une réactivité immédiate et prévisible.
C’est un changement fondamental pour l’expérience utilisateur.
🔸 Économie structurelle
Pour les entreprises, remplacer une API cloud coûteuse par un modèle local permet de réduire drastiquement les coûts récurrents, tout en offrant une latence plus stable et maîtrisée.
Moins de dépendance externe, moins de variabilité financière.
Vers une IA utilitaire et invisible
Nous nous dirigeons vers une informatique où l’IA ne sera plus perçue comme un service distant, mais comme un composant utilitaire local, aussi banal qu’un correcteur orthographique.
Nos terminaux hébergeront des essaims de petits modèles experts, chacun spécialisé, collaborant en temps réel grâce aux NPU.
Une intelligence :
- invisible
- omniprésente
- totalement privée
Oui. Clairement, ça va être bien. 😁
Si vous souhaitez concevoir une application mobile, une architecture IA on-device ou réduire vos coûts d’inférence, n’hésitez pas à nous contacter et parlons-en ensemble. 😊